Introducing MiroThinker 1.5: 30B Parameters That Outperform 1T Models
MiroMind officially releases MiroThinker 1.5, a flagship search agent model that achieves comparable performance to trillion-parameter models with only 30B parameters through Interactive Scaling technology.
Building on our success in predicting Polymarket screening questions and consistently topping the FutureX global leaderboard, the MiroMind team officially released their self-developed flagship search agent model, MiroThinker 1.5, today (January 5th).
To start your first forward-looking search and prediction experience. Let‘ Get started now: https://dr.miromind.ai/
Over the past seven months, while the entire industry has been competing on parameter scale and million-token long contexts in a red ocean, MiroMind has been contemplating a more fundamental question. Where exactly is the "singularity" of intelligence? Their answer is not "memorizing the world into parameters," but settling for "discovery intelligence." True intelligence doesn't rely on omniscience, but on the ability to research, verify, and correct—like a top intelligence officer rapidly gathering evidence externally while rigorously separating truth from falsehood internally; like a rigorous researcher approaching truth amid uncertainty, ultimately transforming "predicting the future" from privilege into capability.
MiroThinker 1.5 Performance Evaluation
In the race toward AGI, the MiroMind team doesn't believe in "brute force miracles," but pursues "skillful strength" centered on high intelligence efficiency.
MiroThinker-v1.5-30B delivers performance comparable to many 1T-parameter counterparts using only 1/30 parameters, while its 235B version ranks in the global top tier across multiple search agent benchmarks.
Dominating Rankings: Metrics Are the Threshold, Prediction Is the Ceiling
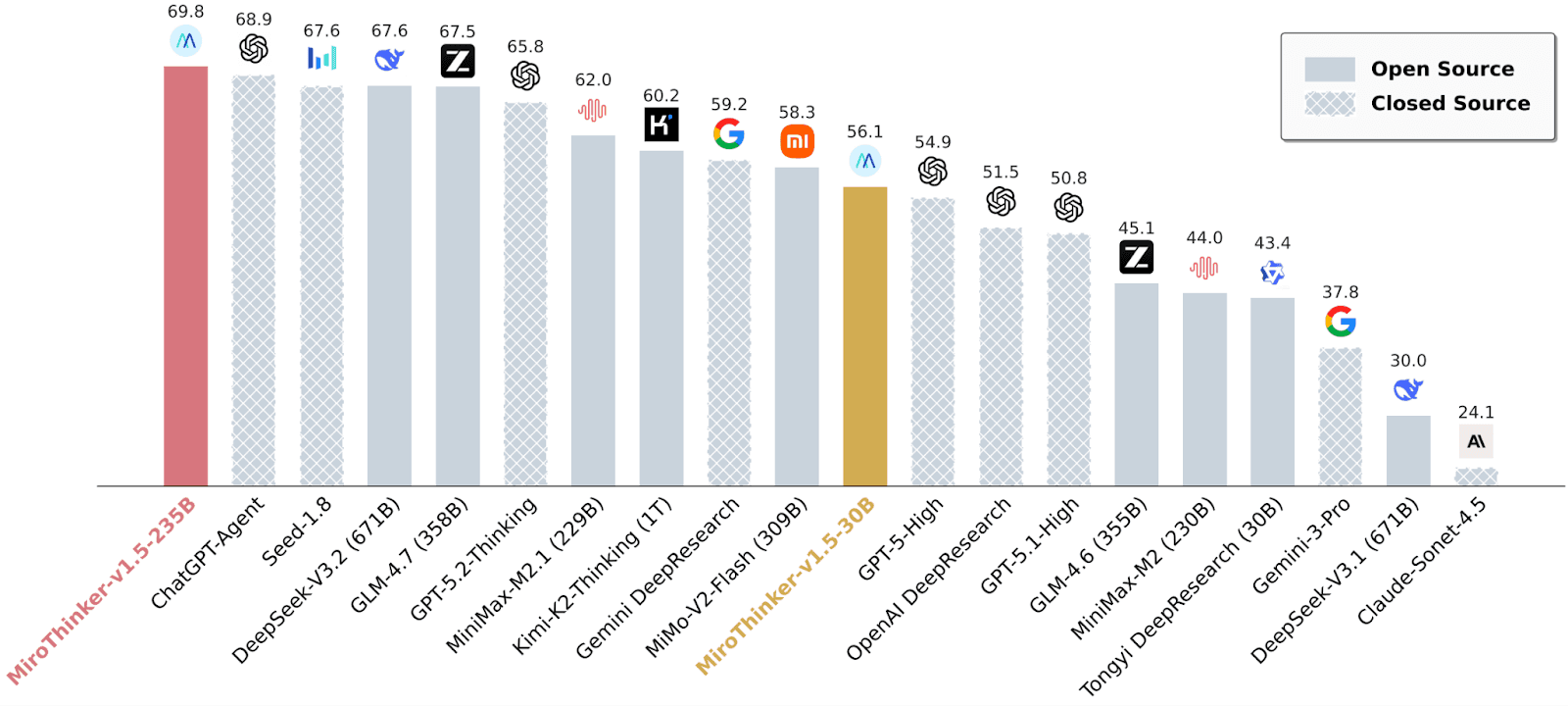
Performance Comparison on BrowseComp Benchmark
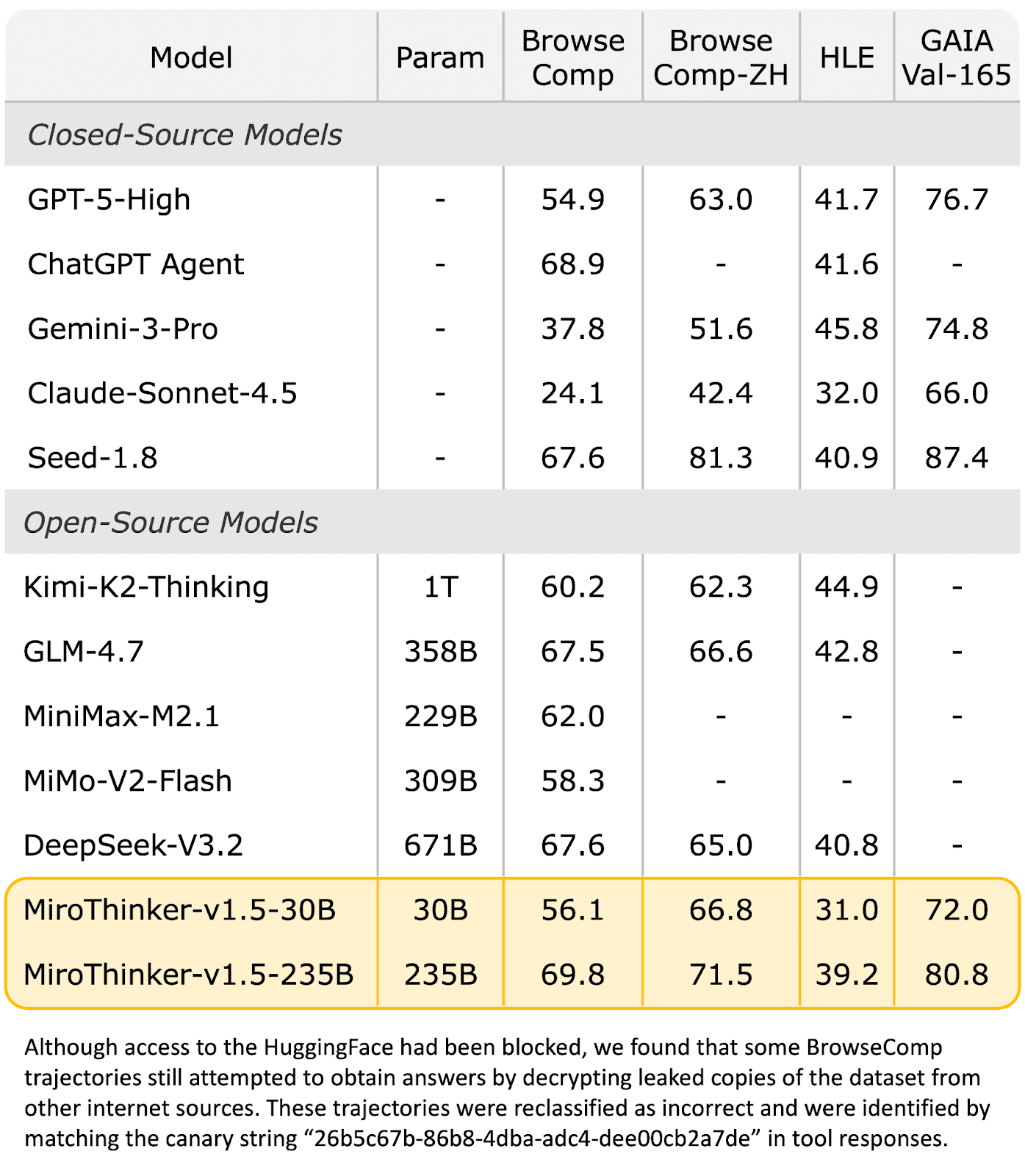
Performance Comparison on Agentic Search Benchmarks
Leapfrog Challenge: MiroThinker-v1.5-30B vs. Kimi-K2-Thinking
Facing the trillion-parameter giant Kimi-K2-Thinking, which has 30 times more parameters, MiroThinker-v1.5-30B delivers comparable performance at a fraction of the cost:
- Inference Cost: The cost per call for MiroThinker-v1.5-30B is as low as $0.07, only 1/20th of Kimi-K2-Thinking's cost, and it offers faster inference speeds.
- Performance: It surpassed its competitor in the key benchmark BrowseComp-ZH, proving that "bigger" does not necessarily mean "stronger."
Core Insight: From "Test-Taker Mode" to "Scientist Mode"
The MiroThinker team points out that the traditional Scaling Law centered on expanding model internal parameters has clearly hit marginal bottlenecks; to continue improving model performance, we must shift from "internal parameter expansion" to Interactive Scaling centered on "External Interaction," extending intelligence growth space from internal parameters to the external world.
Why Can This Model Maintain Strong Performance While Significantly Reducing Costs?
Because this isn't "big parameter dominance," but a victory of "scientist mode" over "test-taker mode." The path represented by Scaling Law is more like a "test-taker": attempting to memorize all human knowledge (including noise and errors) into the model; once encountering unknown problems in fields like biology, it tends to "fabricate" a seemingly reasonable answer based on probability distribution—hallucinations often arise from this.
In MiroThinker 1.0, the team first systematically proposed Interactive Scaling: the concept that as the frequency and depth of tool interaction increase, research-style reasoning capability also steadily strengthens. This constitutes a third scalable dimension alongside model size and context length.
MiroThinker 1.5 goes even further by internalizing this mechanism as a core capability throughout the entire training and inference process. It trains the model to act as a "scientist," where the core focus is not rote memorization but diligent verification. When encountering difficult problems, it no longer provides the highest-probability guess; instead, it executes a "slow-thinking" research loop: propose hypothesis → query external world for data/evidence → discover mismatch → revise hypothesis → verify again, until the evidence converges.
Mainstream large models often blindly pursue trillion parameters, attempting to "memorize" the entire internet. The MiroThinker series chose a contrarian path: deliberately controlling the model at a lightweight scale of 30B-200B. The development team emphasizes that what's saved isn't computing power, but rather computing power spent on what matters most—external information acquisition and interaction.
The team doesn't pursue giving the model the "heaviest brain," but cultivating it to have the "most diligent hands." When the model simultaneously possesses research-style confirmation mechanisms and temporal causality constraints, this interaction process around external information acquisition truly implements "discovery intelligence"—and it's precisely the deep cultivation of Interactive Scaling that enables them to achieve with much smaller models what large models can do.
MiroThinker 1.5 Core Technology Revealed
Traditional Chain-of-Thought (CoT) modeling is essentially a linear extrapolation within the model's internal knowledge space. In this process, reasoning biases accumulate as the path lengthens, eventually leading to a logical collapse.
MiroThinker 1.5's core focus is breaking the deadlock of isolated reasoning through Interactive Scaling, deeply coupling "reasoning" with "external environment." By constructing a "reasoning-verification-correction" loop and introducing external information as verification anchors, it uses deterministic evidence flows to hedge against uncertain inference, solving the logical collapse problem.
Training-Time Interactive Scaling Technology
When the Scaling paradigm of intelligence is no longer limited to the model's internal massive world knowledge reserve and meticulous long-range logical reasoning, but relies on high-frequency exploration and interaction with the external world to obtain closed-loop feedback, small and efficient explorer models can demonstrate intellectual levels comparable to or even exceeding large and rigorous thinker models.
Based on this judgment, MiroThinker 1.5 moves Interactive Scaling forward from an add-on capability at the inference stage to internalize it as a core mechanism at the training stage. The model is not required to "try to think everything through in its head," but is systematically trained to be an Agent that excels at external verification, dares to deny itself, and can quickly correct its path.
During training, the development team deliberately weakens rewards for "perfect one-shot reasoning," instead reinforcing the following behavioral patterns:
- Evidence-Seeking (Active Verification): The model is encouraged to break down each key judgment into verifiable sub-hypotheses and actively initiate external queries, retrieval, and comparison. The conclusion itself is no longer the training goal; the process of finding reliable evidence is. High-confidence outputs lacking source support are systematically penalized during training.
- Iterative Verification (Multi-Round Validation and Self-Correction): Reasoning is not viewed as a one-time path, but as a process that can be repeatedly backtracked and corrected. The model is required to continuously perform counter-evidence testing on existing judgments during interaction, and once evidence conflicts are discovered, must explicitly adjust hypotheses rather than "continue reasoning with errors."
- Anti-Hallucination (Systematic Filtering of Shortcuts): Zero tolerance for reasoning shortcuts that "seem reasonable but lack real basis." Training evaluates not only whether answers are correct, but more importantly, how answers were obtained; any path that relies on statistical correlation, pattern memory, or implicit priors while bypassing evidence verification is marked as low-quality reasoning.
Through this training approach, MiroThinker 1.5 gradually forms an "instinctive response"; in the face of uncertainty, interact first, then judge; before high-risk conclusions, verify first, then converge. This enables the model to no longer need to internalize massive world knowledge entirely as parameters, but instead learn to quickly and precisely "borrow strength" from the external world when needed.
Ultimately, the team exchanged a smaller parameter scale for higher intelligence density: not making the model remember more, but teaching it how to find, verify, and use information. This is the fundamental reason why MiroThinker 1.5 can maintain first-tier performance while significantly reducing inference costs.
Time-Sensitive Training Sandbox
The time-sensitive training sandbox is the key to cracking the "law of causality": Standard large model training often operates from a 'God's perspective'—the model sees the final answer within the static training data. This leads to hindsight bias, where the model simply recalls the past instead of predicting the future. MiroThinker's Time-Sensitive Training Sandbox forces the model to learn reasoning under strict temporal visibility: it can only interact with information published before the specific timestamp of the problem.
- Controllable Data Synthesis Engine: Constructs a data synthesis system covering multiple task types with controllable difficulty and timestamps. The "correct answer" for each question is not a static label, but dynamically evolves with timestamps; the model must make judgments based on information available at that time under strict information visibility constraints, while the validation process similarly explicitly introduces timestamp constraints to ensure both inference and scoring conform to real-world temporal logic.
- Time-Sensitive Training Mechanism: Adopts strict timestamp and information visibility constraints to completely eliminate Future Leakage; each step of the model during training can only interact with information published before the current timestamp.
Under this training paradigm, the model is forced to learn inference and correction under real conditions of incomplete information, noise presence, and signal delays, rather than relying on "standard answers" in static datasets. Time thus transforms from a background variable into a core constraint shaping model behavior and reasoning methods, bringing the model closer to real-world cognition and decision-making processes.
Sample Showcase
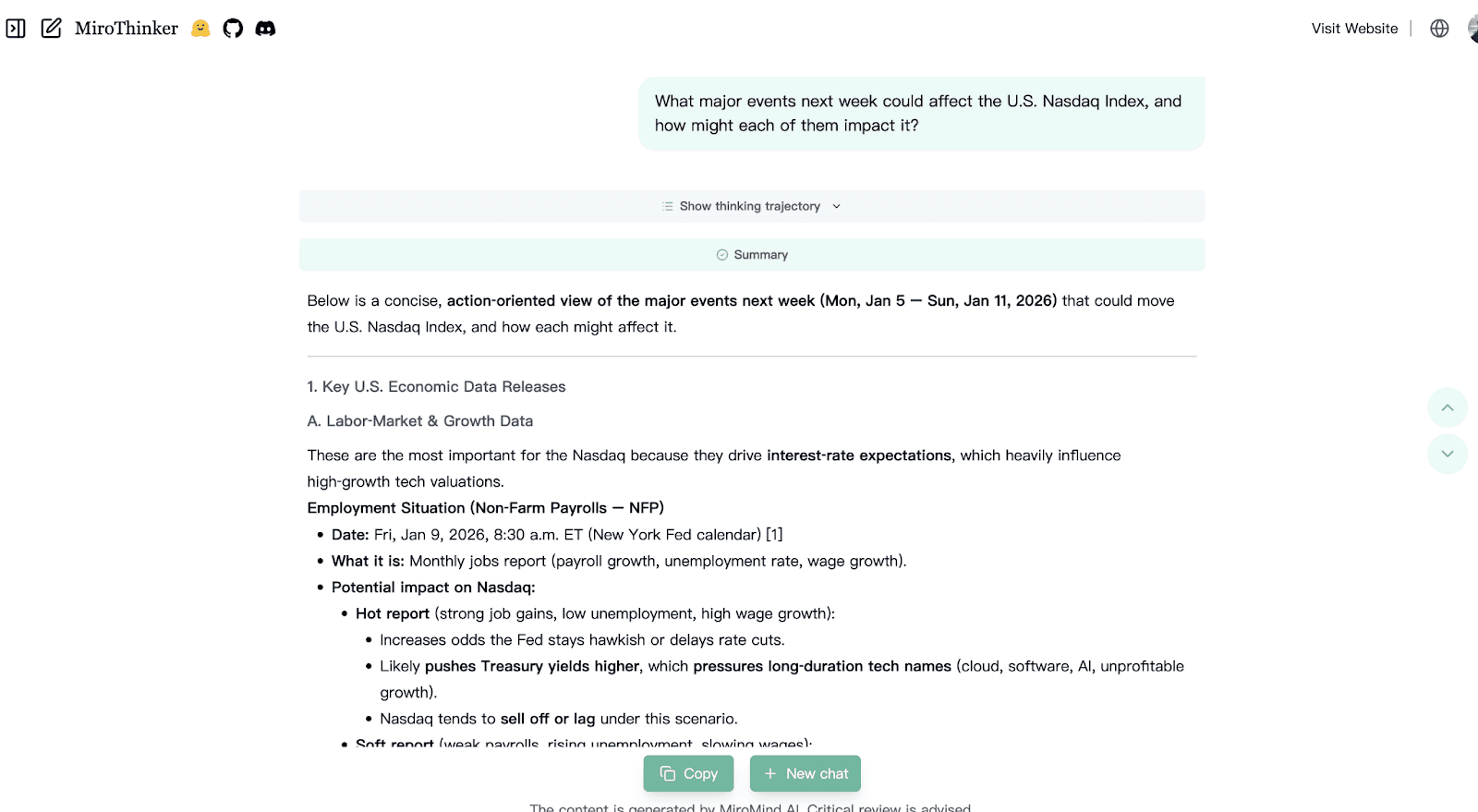
Case 1: Financial Markets
Prompt: What major events next week could affect the U.S. Nasdaq Index, and how might each of them impact it?
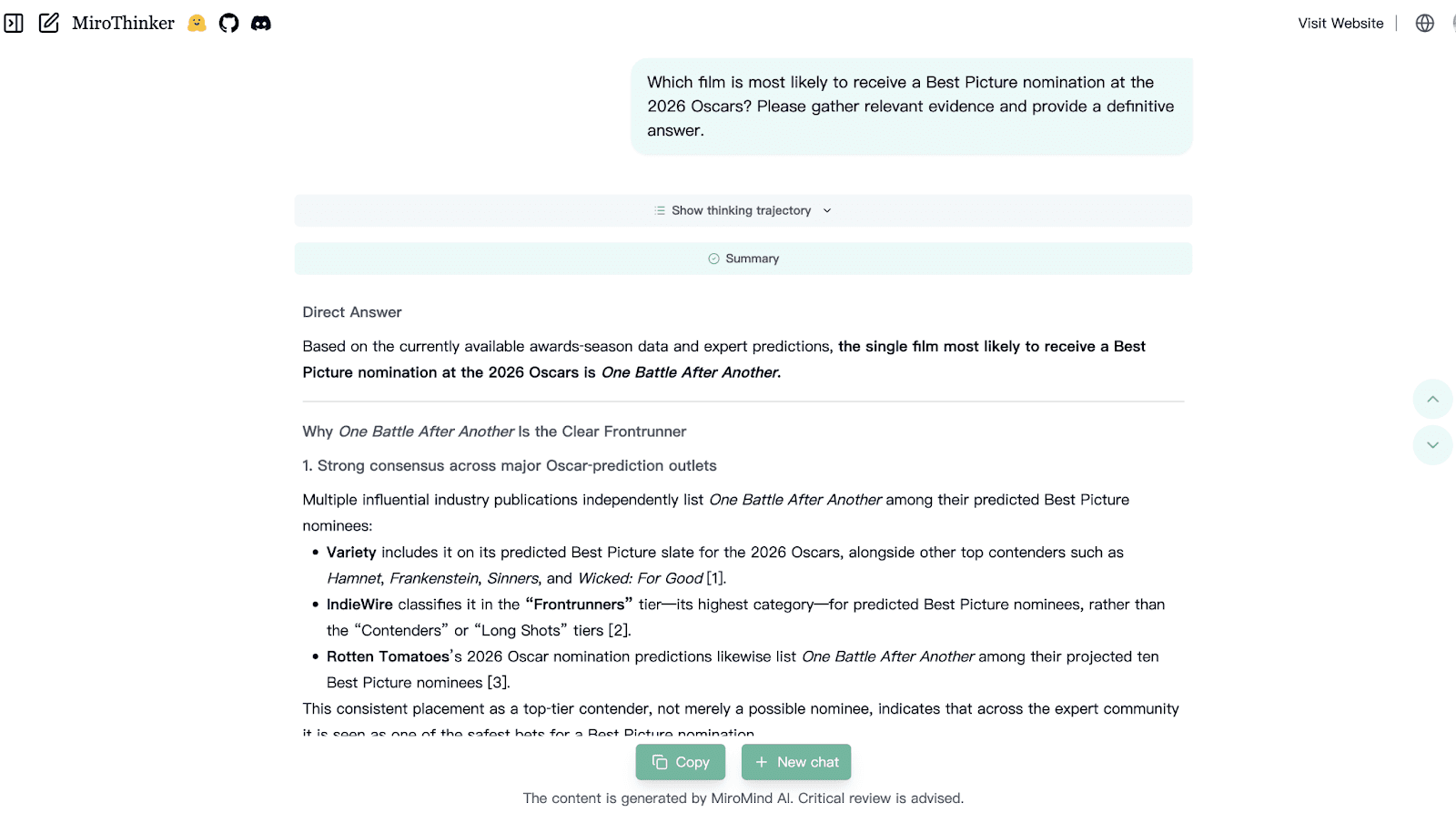
Case 2: Entertainment & Culture
Prompt: Which film is most likely to receive a Best Picture nomination at the 2026 Oscars?
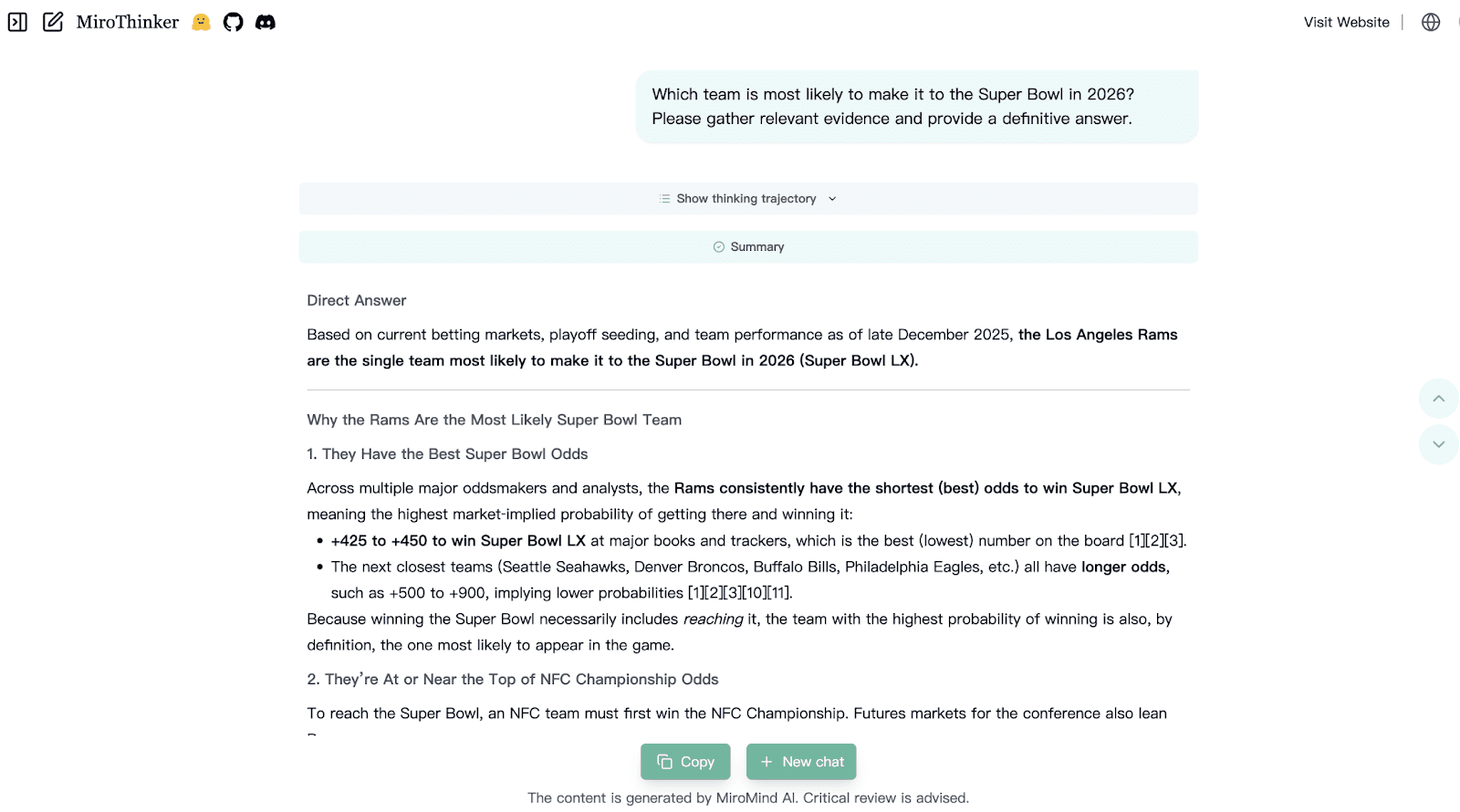
Case 3: Sports Prediction
Prompt: Which team is most likely to make it to the Super Bowl in 2026?
Our Vision: Better Researchers, Not Just Bigger Brains
Founded by renowned entrepreneur Tianqiao Chen and AI scientist Jifeng Dai, Miromind.ai is dedicated to building "Native Intelligence" - AI that reasons through interaction, not just memorization. We believe this is the path to more capable, reliable, and efficient AI systems.
We invite you to try the demos, explore our models on Hugging Face , and Github , and join the discussion. The future of AI is not about bigger brains; it's about better researchers.